
Decision tree
Decision tree is an essential algorithm in Machine Learning field. Using Decision tree can express all possible functions among the data. Understanding the decision tree requires us to know entropy in the first place.
Entropy
Consider we flip an unbiased coin, and we can get head and tail both in 50% chance. However, if we flip a biased coin, we can get head in 90% chance and tail 10% chance. It is the most possible to have a head instead of a tail. We can see we are less surprised to flip this biased coin. Now, let’s define surprise with probability. $$H(p) = -\sum p _ i log _ 2(p _ i)$$ It is the self entropy of the event with probability p. Because probability is always negative. Although we have a negative symbol, the entropy is still positive.
Now we can see flipping unbiased coin’s entropy is 1. Flipping biased coin’s entropy is just 0.469. We can easily prove that the entropy will become the maximum when the probability distribution is uniform.
The key idea here is that entropy represents surprise, uncertainty. The most important idea in machine learning is to reduce uncertainty!
We also could get conditional entropy, $H(X|Y)$, which means the entropy of X when given Y.
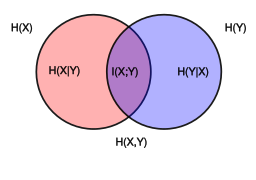
$$H(Y|X) = \sum p(X=x _ i) H(Y|X=x _ i)$$
In the middle is I(X; Y), which is called mutual information. If it is zero, it means X and Y are independent with each other. It means the entropy when X and Y both happened.
Decision tree
Here we discuss the most basic binary decision tree. In each attribute, it just has two possible values.
The algorithm is quite simple. Consider we have 10 attributes, we can test each attribute to see known which one could get minimum entropy. In other words, we want to know that given which attribute could help us get the lowest entropy with the rest of attributes.
$$A^* = min H(L|A) = min \sum p(A=a _ i) H(L|A=a _ i) = max I(L;A)$$
It is a greedy algorithm, from the top of the tree, we can know the attribute that contributes the most information in the data — known that one can help us reduce the uncertainty.
The problem is overfitting for decision tree. It is possible for us to have so many branches and overfit the training datasets. The idea to solve the problem is to do pruning on the tree. Pruning of the decision tree is done by replacing a whole subtree by a leaf node. Also with K-fold validation can help us.