
In this blog, I introduce a way to do streaming processing with Kafka and Spark Streaming. In the workflow, Kafka is used as a message queuing system and Spark Streaming process data from Kafka and save them into MySQL database.
Install the software
In this section, we need to install these things on the machine.
- Hadoop
- Spark
- Kafka
- MySQL
![]()
In the beginning, we need to download Hadoop from the official website and then extract them. Next, we need to set the environment path.
wget -P ~ http://archive.apache.org/dist/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
tar xf hadoop-2.8.0.tar.gz
echo HADOOP_HOME=~/hadoop-2.8.0 >> ~/.bashrc
![]()
We could use a similar procedure to install the Spark.
# download spark
wget -P ~ http://mirrors.advancedhosters.com/apache/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz
# set PATH
echo SPARK_PATH=~/spark-2.4.0-bin-hadoop2.7 >> ~/.bashrc
source ~/.bashrc
Installing the MySQL is the easiest one, we only need to use sudo apt-get install mysql-server to install it. One thing to remember is that we only need to use sudo mysql to login MySQL as the root user.
![]()
Installing Kafka is a bit difficult because we need to set up Zookeeper to start the Kafka service. The detailed procedure you could find here. We can use
~/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 5 --topic xxxx
to test the installation result.
Setup Kafka producer
Because we did not have streaming data, we need to produce from the Kafka Producer API. Here is a straightforward java project. The Kafka Producer API you can find here
The main part code is here. In my code, I sent the data to different partition based on fid. For the completed example, you can visit here.
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
JsonParser parser = new JsonParser();
BufferedReader bufferedReader = new BufferedReader(new FileReader("xxxxxx.log"));
String line = null;
while ((line = bufferedReader.readLine()) != null) {
JsonObject jsonObject = parser.parse(line).getAsJsonObject();
if (jsonObject.get("fid")!=JsonNull){
int fid = Integer.parseInt(jsonObject.get("fid").getAsString());
producer.send(new ProducerRecord<String, String>("xxxxx", fid % 5, null, line));
}
}
bufferedReader.close();
producer.close();
Set up Spark Streaming
This part is not as easy as I thought. Here I focused on how to make pySpark Streaming work.
In the Streaming app, we need to set up a StreamingContext and then create a stream to listen to the topic from Kafka.
sc = SparkContext(appName="PythonSparkStreamingKafka")
sc.setLogLevel("WARN")
ssc = StreamingContext(sc,60)
kafkaStream = KafkaUtils.createStream(ssc, 'localhost:2181', 'spark-streaming', {'xxx':1})
Next, we view each stream object as Discretized Streams, which means each object is an RDD here. More detailed information about DStream you can find here.
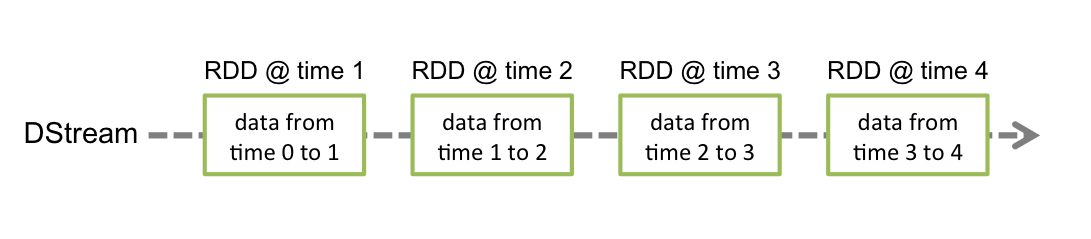
Then we can map each RDD and save them into MySQL.
def getSparkSessionInstance(sparkConf):
if ('sparkSessionSingletonInstance' not in globals()):
globals()['sparkSessionSingletonInstance'] = SparkSession\
.builder\
.config(conf=sparkConf)\
.getOrCreate()
return globals()['sparkSessionSingletonInstance']
def convert_json2df(rdd):
if rdd.isEmpty():
return
print(rdd.count())
spark = getSparkSessionInstance(rdd.context.getConf())
df = spark.createDataFrame(rdd)
df = df.toDF('uid','fid','tid','date','ip','credits','groupid')
df.write.format("jdbc")\
.option("url", "jdbc:mysql://localhost:3306/xxxx")\ #db name
.option("dbtable", "log")\ #table name
.option("user", "user")\
.option("password", "xxxx")\
.option("driver", 'com.mysql.jdbc.Driver')\
.mode('append').save()
lines = kafkaStream.map(lambda x: check_json(x)).filter(lambda x: x) \
.foreachRDD(lambda x: convert_json2df(x))
We also need to start the streaming process.
ssc.start()
ssc.awaitTermination()
Last but not least, we need to add several packages to start the Spark Streaming job.
spark-2.4.0-bin-hadoop2.7/bin/spark-submit --packages org.apache.spark:spark-streaming-kafka-0-8-assembly_2.11:2.3.1,mysql:mysql-connector-java:8.0.15 streaming.py